Attention is all you need
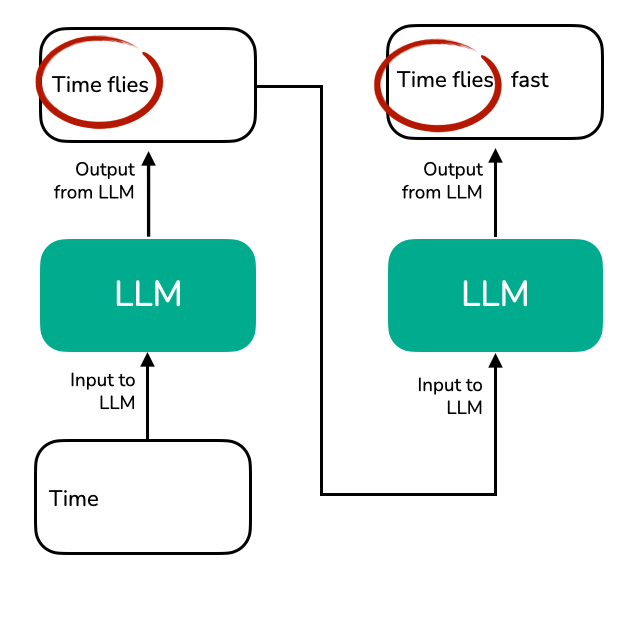
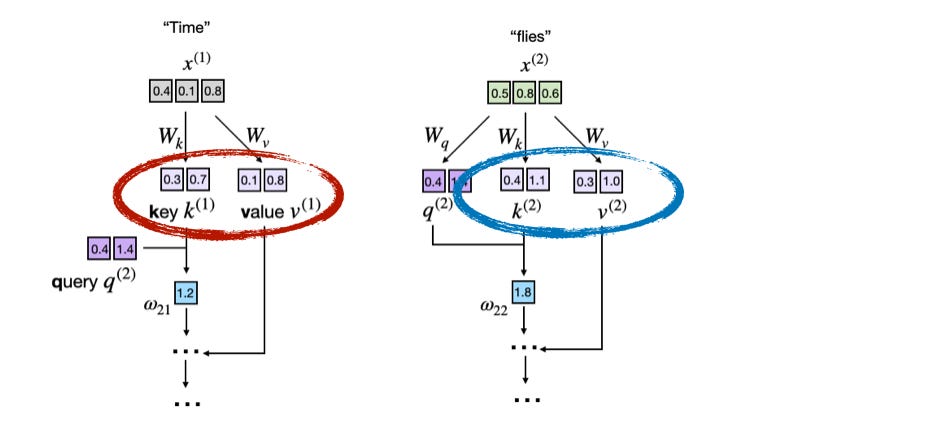
KV Caching
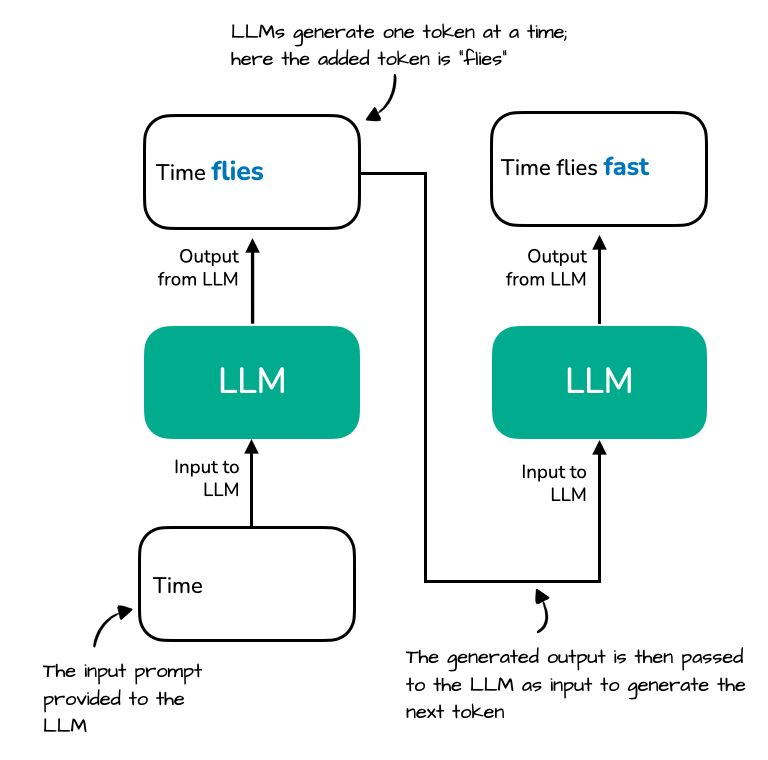
Vergangene Token noch nötig
$$\vec{E} \rightarrow \vec{Q}, \vec{K}, \vec{V}$$
step++
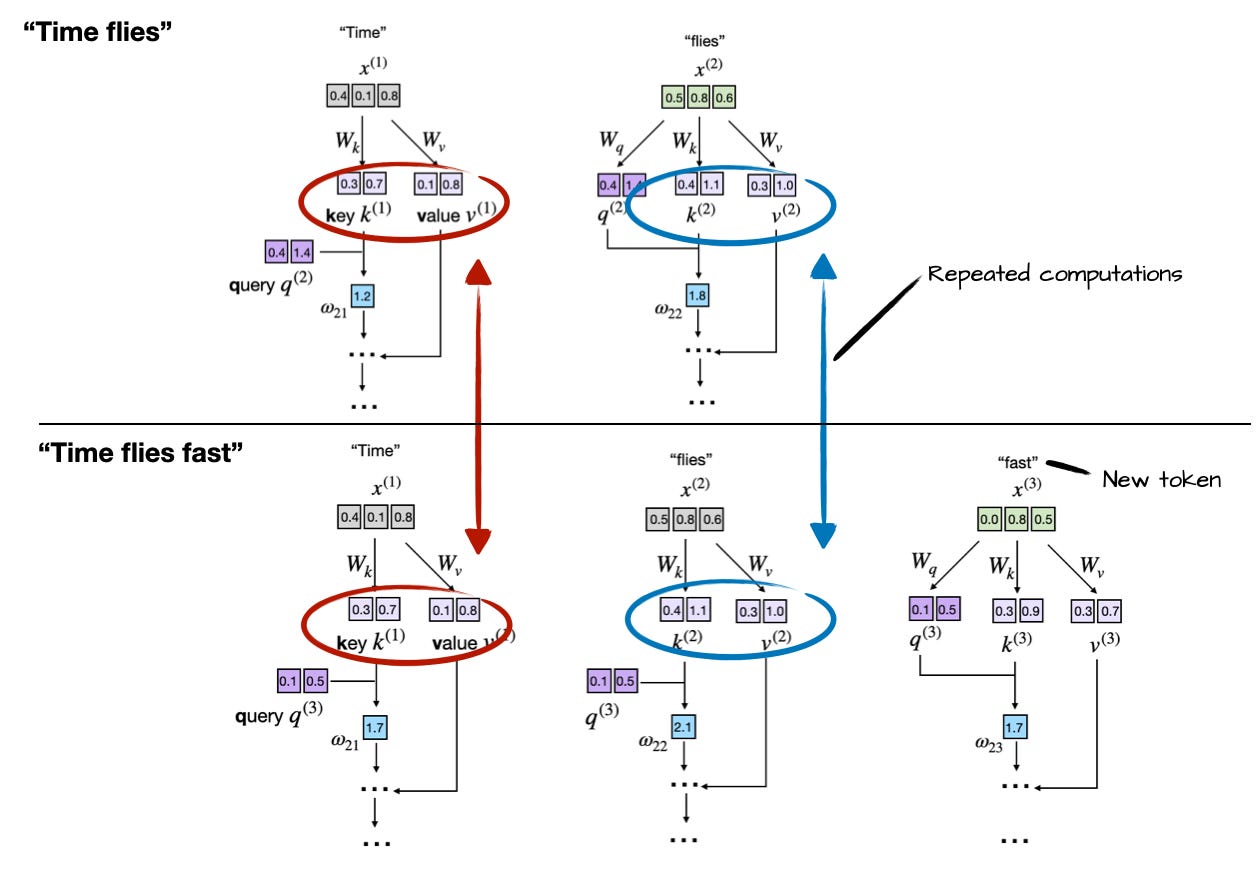
KV Cache
| Step | Input | Normal K/V | Cached K/V | Computed K/V |
|---|---|---|---|---|
| 1 | Time | Time | - | Time |
| 2 | Time flies | Time, flies | Time | flies |
| 3 | Time flies fast | Time, flies, fast | Time, flies | fast |
Quantization
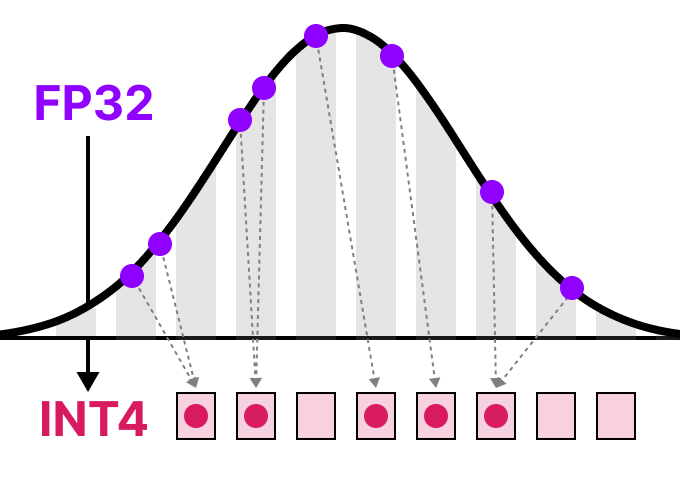
- kleiner
- schneller
- im Idealfall fast gleich gut
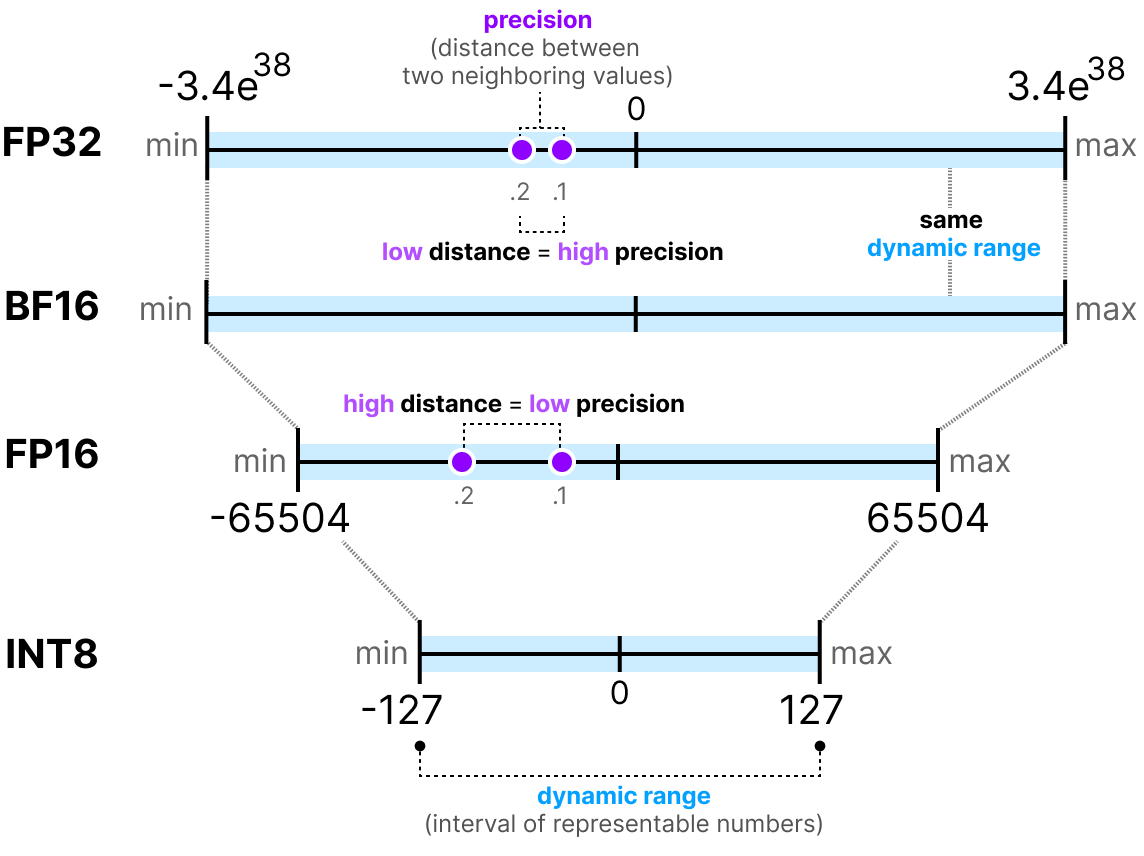
Beispiel
70B Parameter Model
| Datentyp | RAM[GB] |
|---|---|
| FP32 | 280 |
| FP16 | 140 |
| FP8/INT8 | 70 |
2020 GPT3
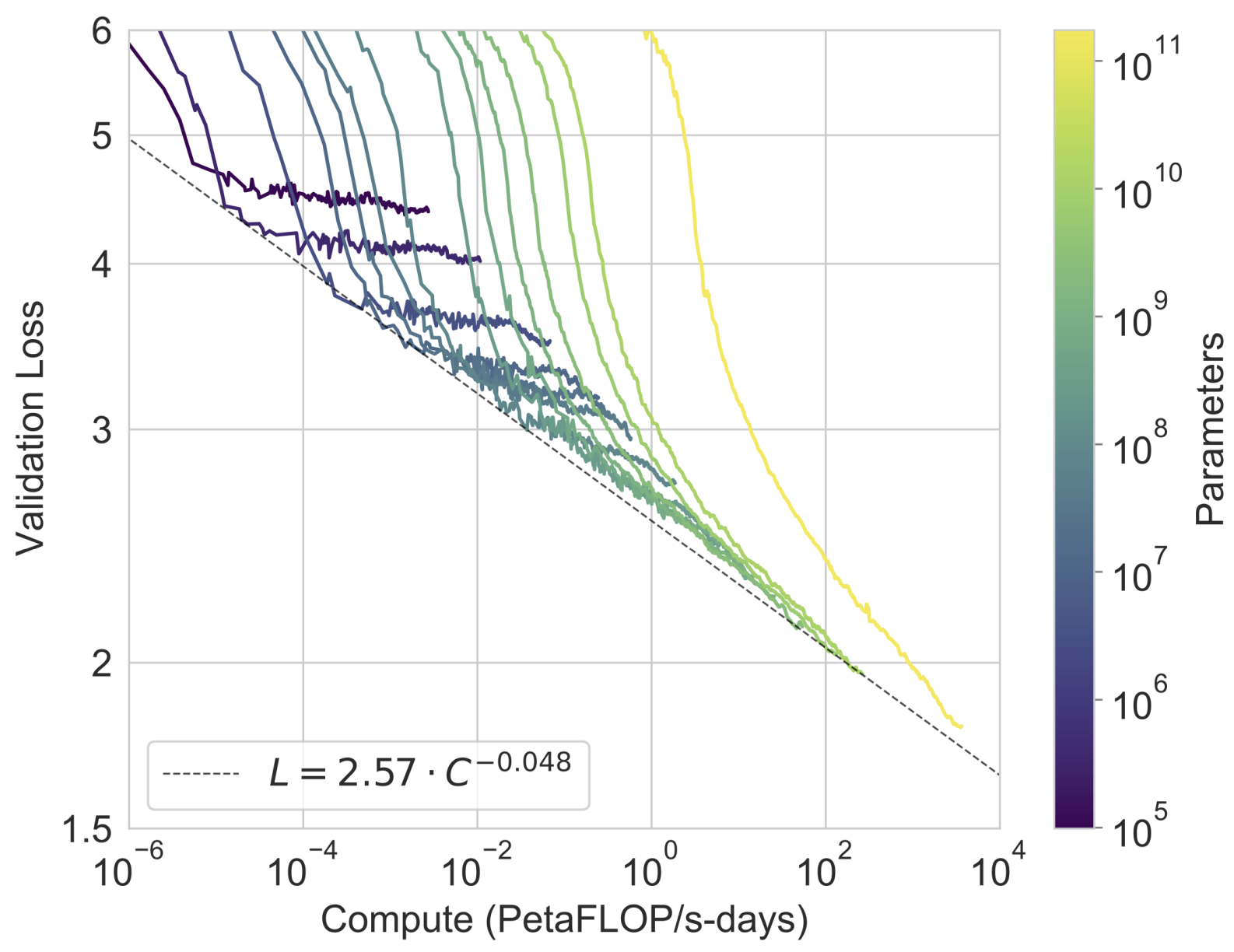
Larger models make increasingly efficient use of in-context information.
[...] reflect on the small 1.5% improvement achieved by a doubling of model size between two recent state of the art results and argue that “continuing to expand hardware and data sizes by orders of magnitude is not the path forward”. We find that path is still promising...
Scaling
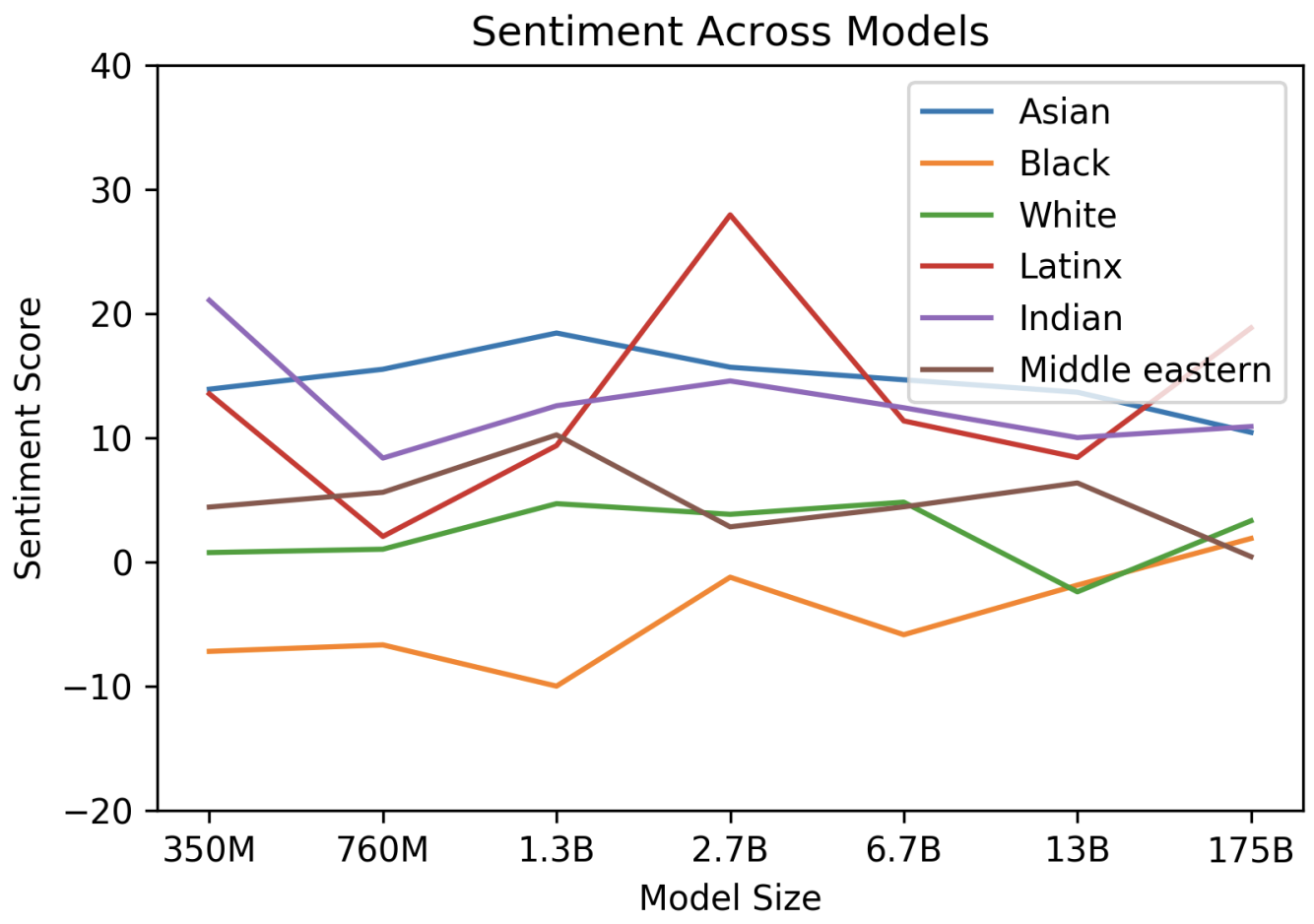
Ethik
Finally, GPT-3 shares some limitations common to most deep learning systems – its decisions are not easily interpretable, it is not necessarily well-calibrated in its predictions on novel inputs as observed by the much higher variance in performance than humans on standard benchmarks, and it retains the biases of the data it has been trained on. This last issue – biases in the data that may lead the model to generate stereotyped or prejudiced content – is of special concern from a societal perspective...
2024 DeepSeek V3
- FP8 Quantization-Aware-Training
- Mixture of Experts
- Latent Attention
- Rotary Position Embedding
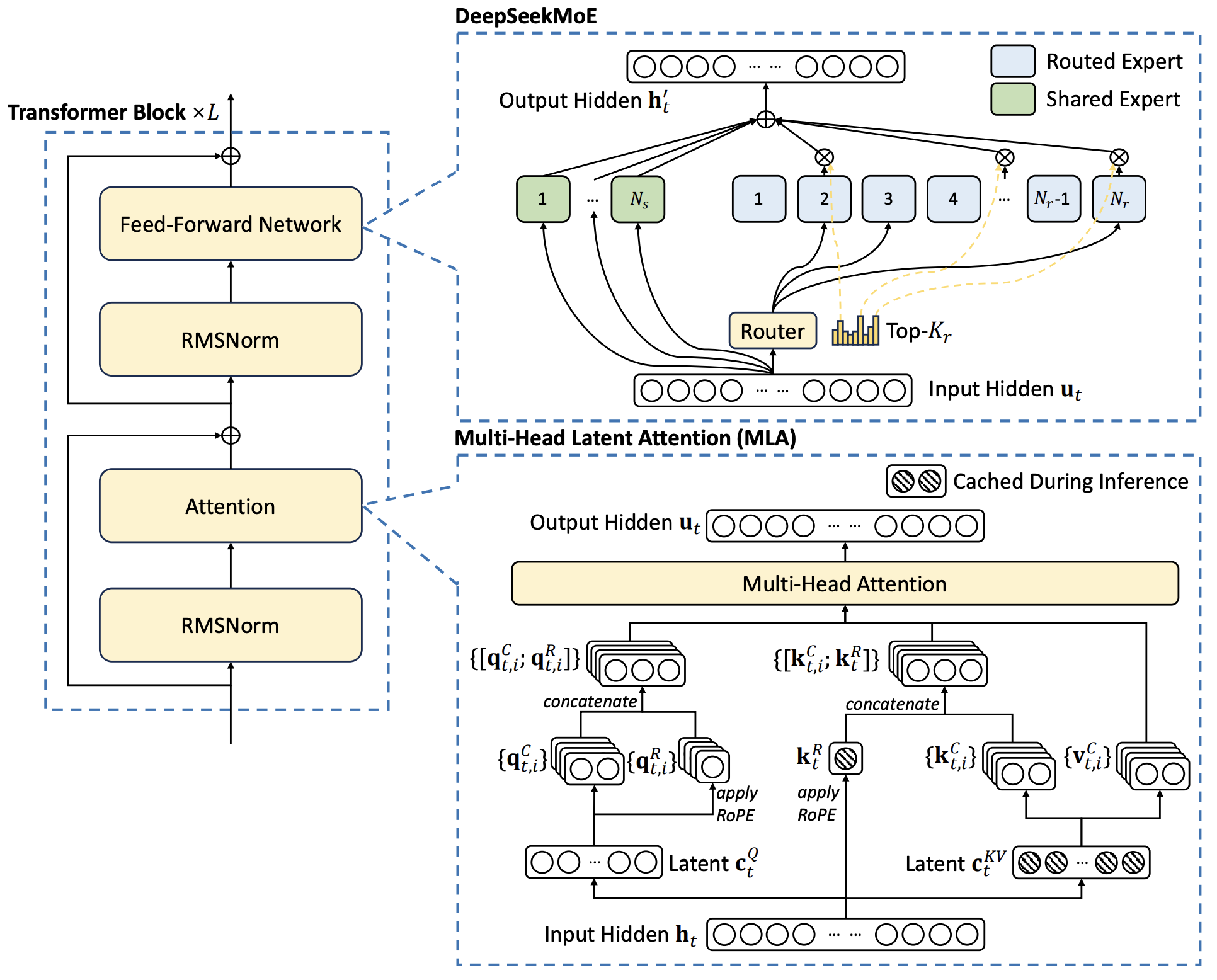
"Experts"

2025 Time Scaling
- GPT3: mehr Parameter ⟹ weniger Loss
- 💡: mehr Zeit ⟹ weniger Loss
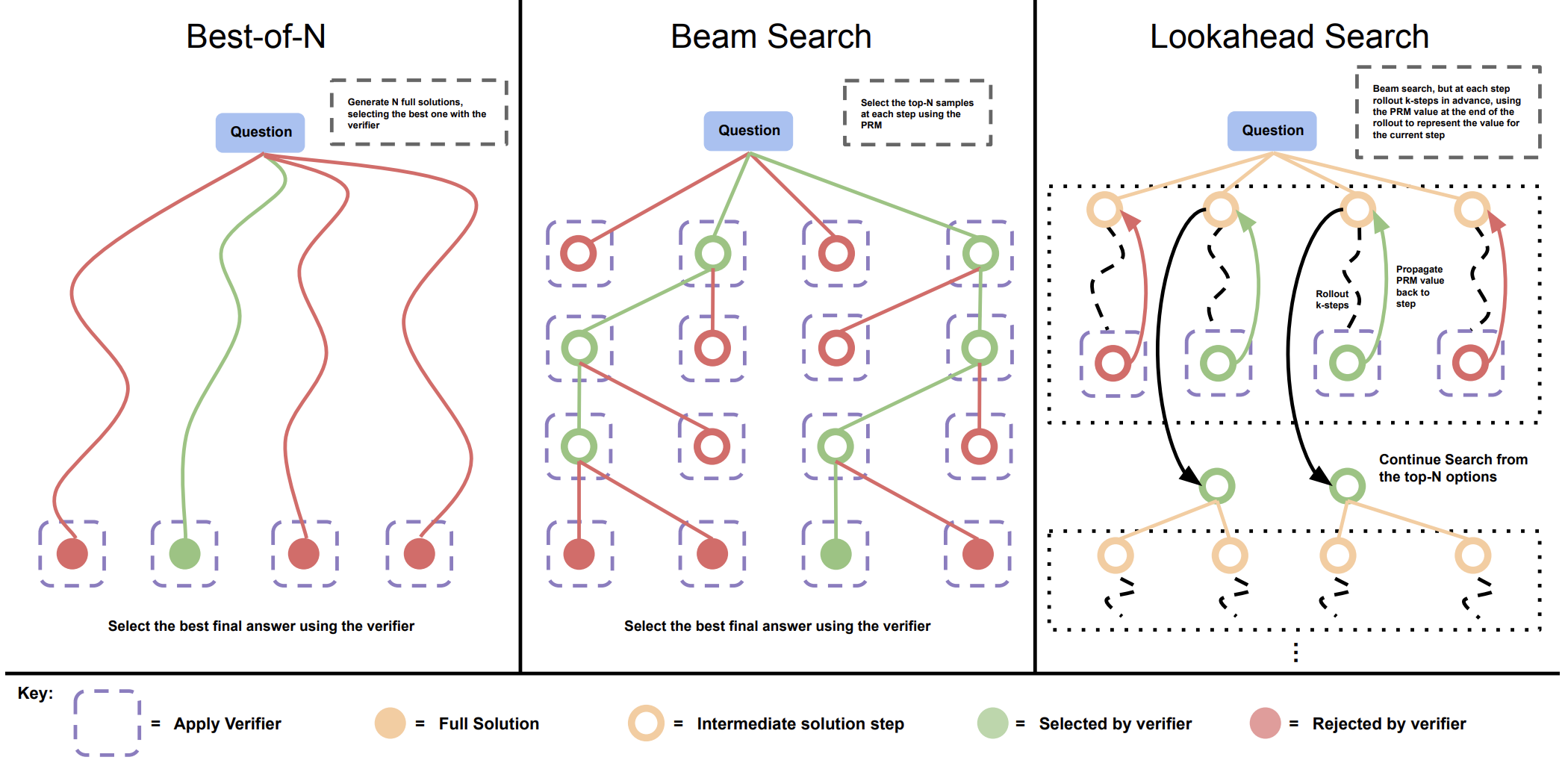
2024 o1 R1
- Trainingsdaten (Supervised Fine Tuning)
- Chain of Thought Prompting

Their dependence on human-annotated reasoning traces hinders scalability and introduces cognitive biases.
Reinforcement Learning (Alpha Go)
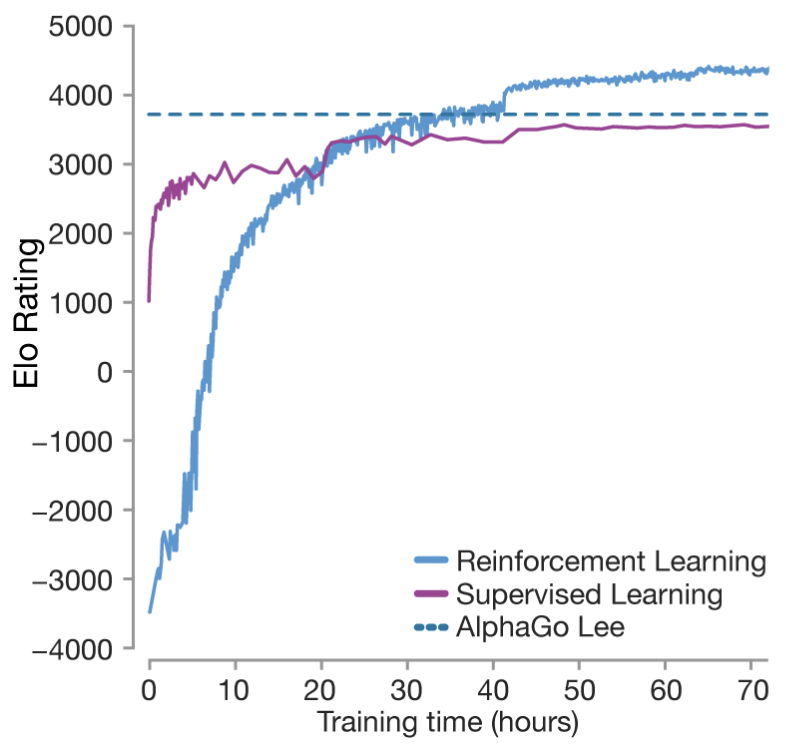
AlphaGo Lee 3800 < AlphaGo Zero 5200
Reinforcement Learning
$$Reward_{rule} = Reward_{acc} + Reward_{format}$$
$$Reward_{acc} \rightarrow Compiler, Leetcode$$
$$Reward_{format} \rightarrow LLM\mbox{ }Judge$$
Furthermore, by constraining models to replicate human thought processes, their performance is inherently capped by the human provided exemplars, which prevents the exploration of superior, non-human-like reasoning pathways.
How to reason?
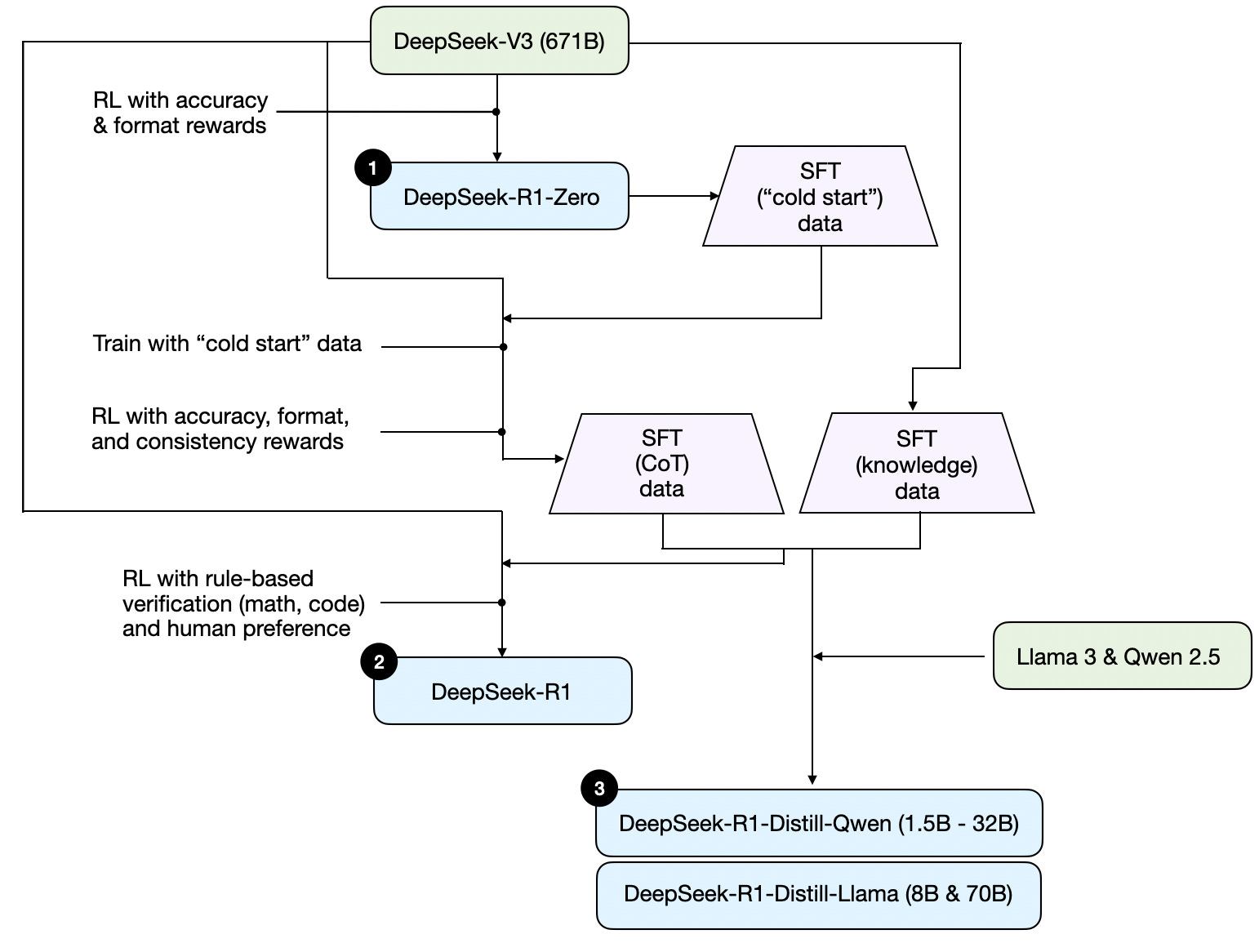
Reasoning? - R1-Zero
