CNN Evolution
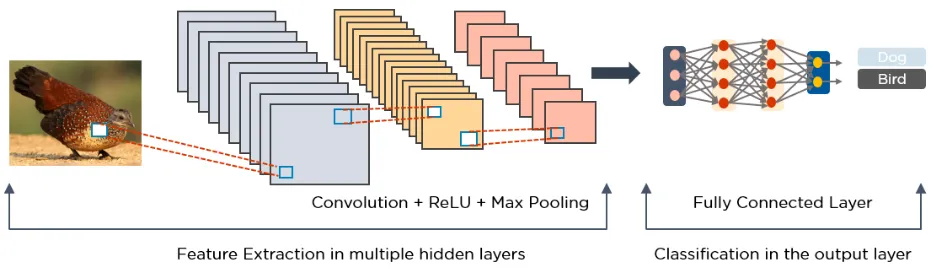
LeNet - 1998

- Convolution
- Average Pooling(kernel_size=2, stride=2)
- Dense
- Dimensionen werden kleiner
- Feature maps mehr
AlexNet - 2012

- Convolution(stride)
- Max Pooling
- tanh -> ReLU
Padding

nn.Conv2d(kernel_size=2, stride=1, padding=1)hält Dimensionen konstant
VGGNet, 2014

- Blocks
- $3 \times 3$ Convolution
kernel_size--
nn.Conv2d(kernel_size=5, stride=1, padding=0)$5\times5 \rightarrow Conv_{5\times5} ⟹ 1\times1$
$5 \times 5 = 25$ Parameter
nn.Conv2d(kernel_size=3, stride=1, padding=0)
nn.Conv2d(kernel_size=3, stride=1, padding=0)$5\times5 \rightarrow Conv_{3\times3} ⟹ 3\times3$
$3\times3 \rightarrow Conv_{3\times3} ⟹ 1\times1$
$3 \times 3 + 3 \times 3 = 18$ Parameter
NiN, 2014

NiN Block
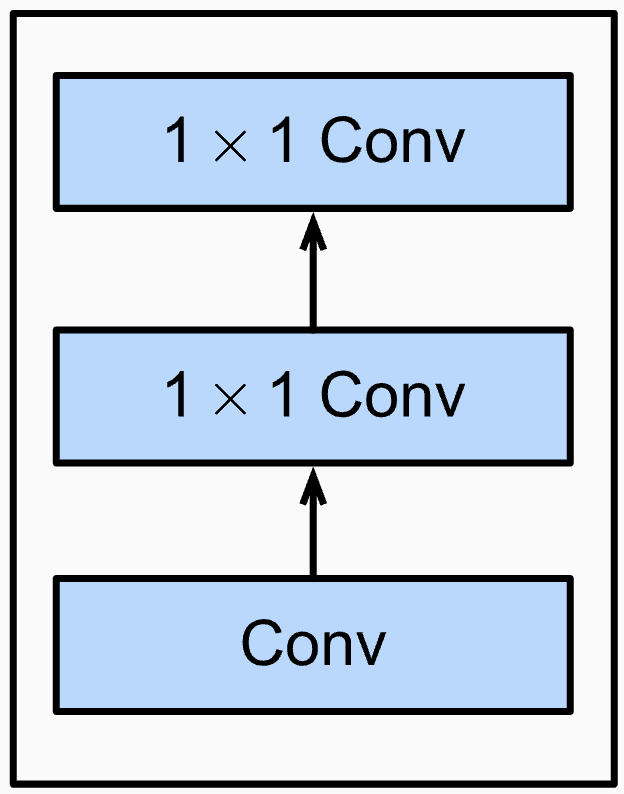
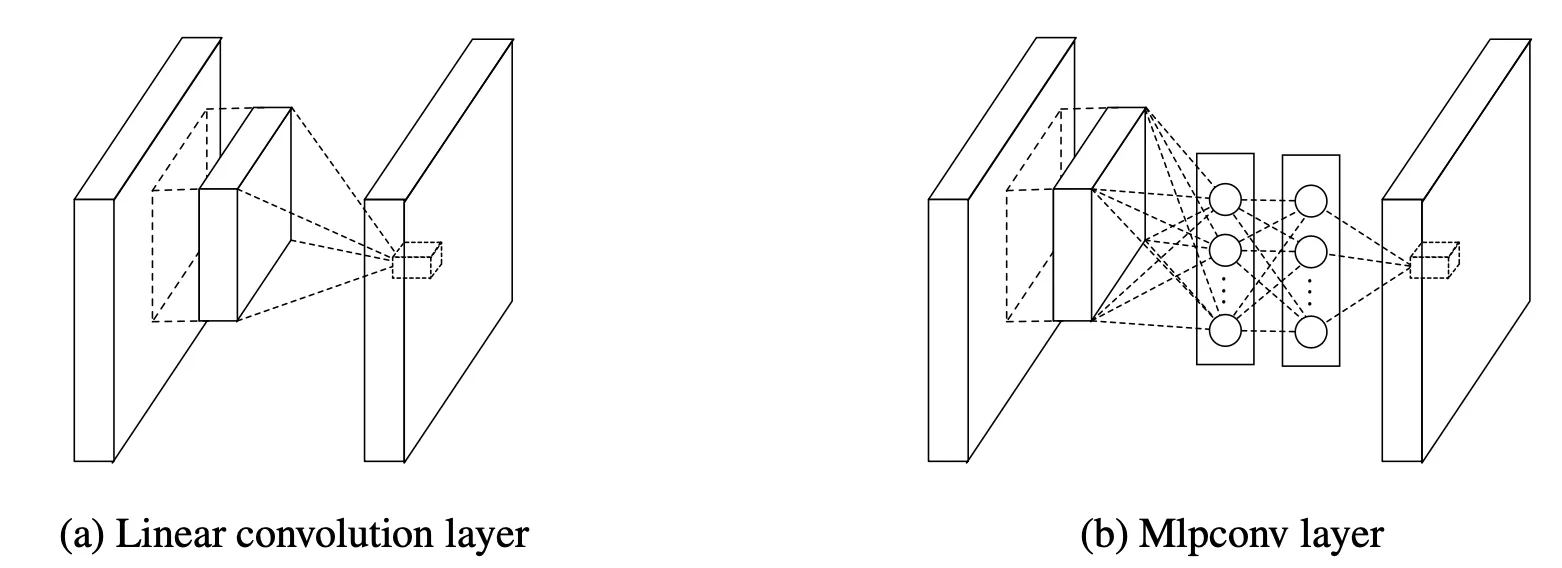
1x1 Convs fungieren als ANN
Fully Convoluted
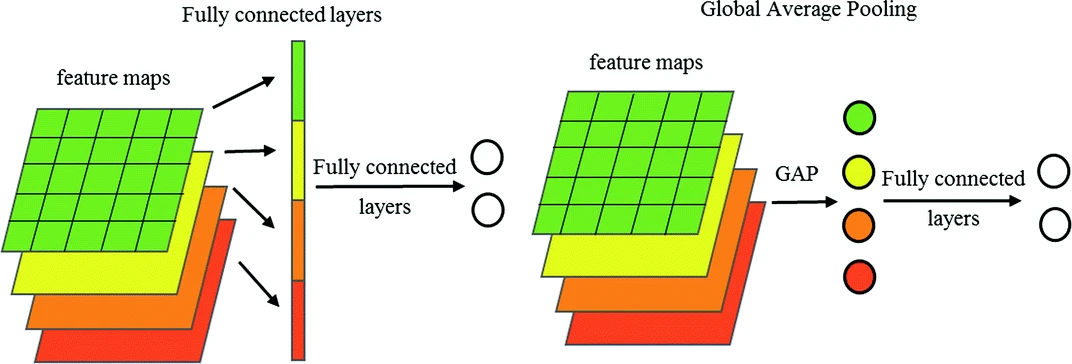
nin_block(num_classes, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)) # output 1x1 je feature mapGoogLeNet, 2014

welche Convolution? ja!
Inception Block

alle Channel werden concatenated
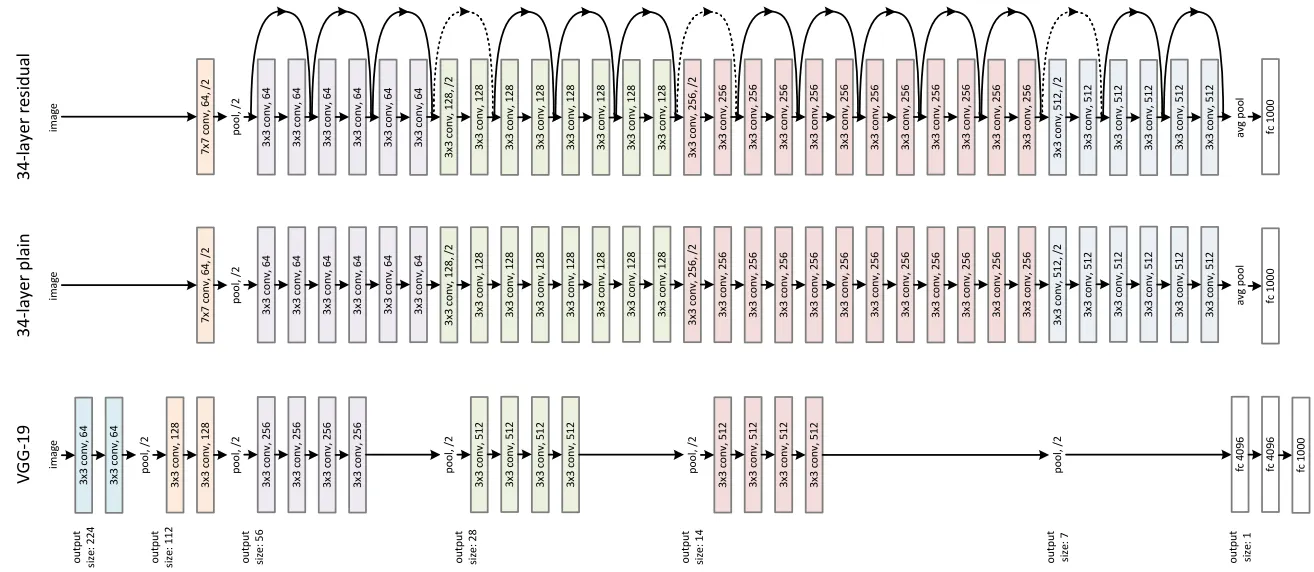
ResNet, 2015
Scaling Problem
- Vanishing/Exploding gradients
- Gradients -> 0/∞
- ✅ ReLU
- ✅ BatchNorm
Deep Learning
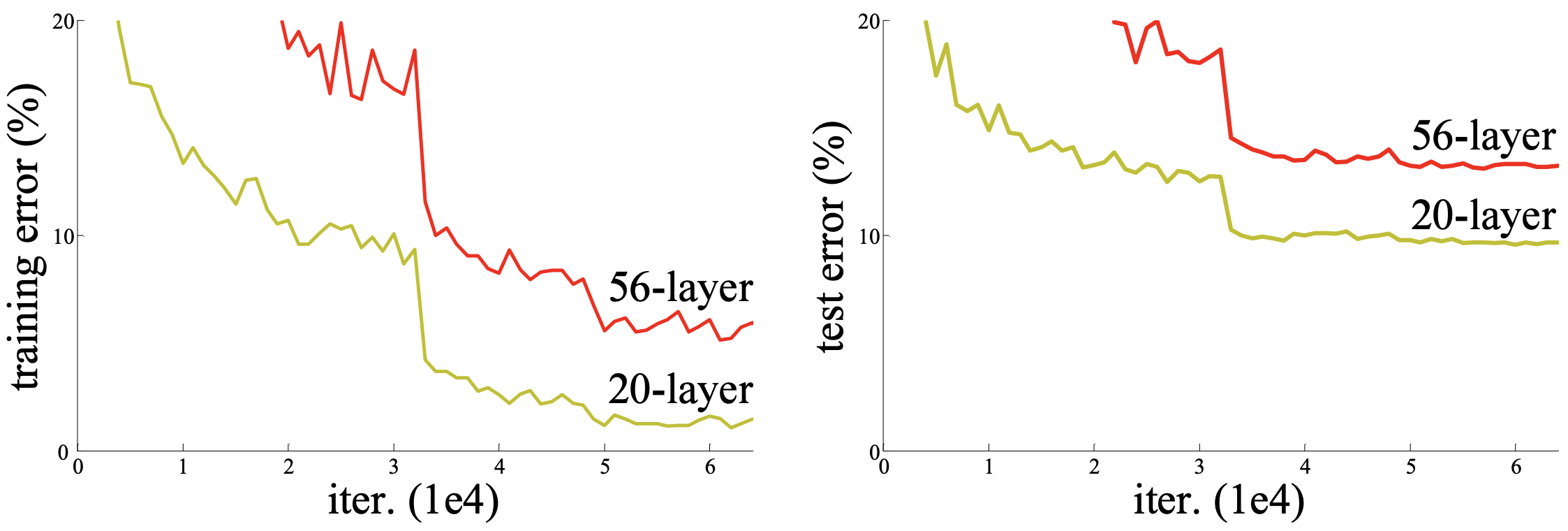
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated and then degrades rapidly.
Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error.
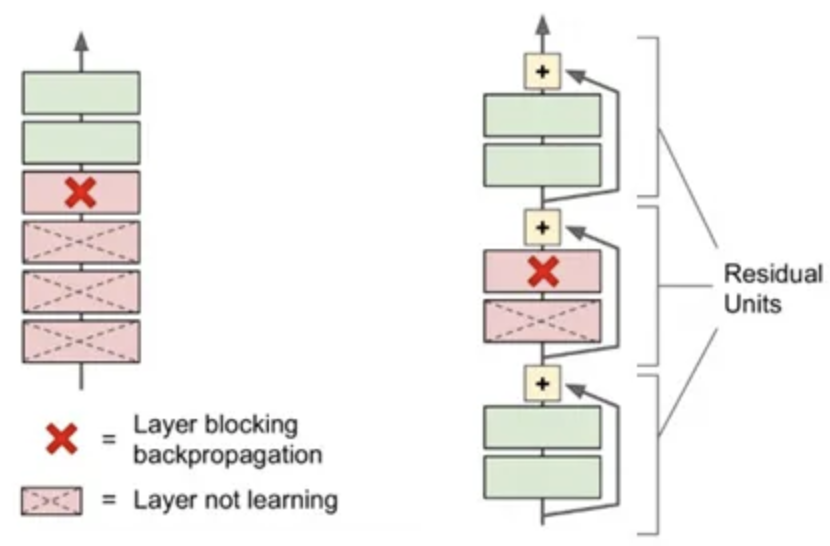
Residual Connections

- $f = a + b$
- $\frac{\partial f}{\partial a} = 1$ local gradient
$\implies \frac{\partial L}{\partial a} = \frac{\partial L}{\partial f} \cdot \frac{\partial f}{\partial a} = 42 \cdot 1 = 42$ global gradient
$\implies \frac{\partial L}{\partial b} = 42$
$\implies + $ verteilt den upstream gradient
‐‐‐‐‐‐‐‐‐‐‐

1x1 Conv falls Channels nicht passen
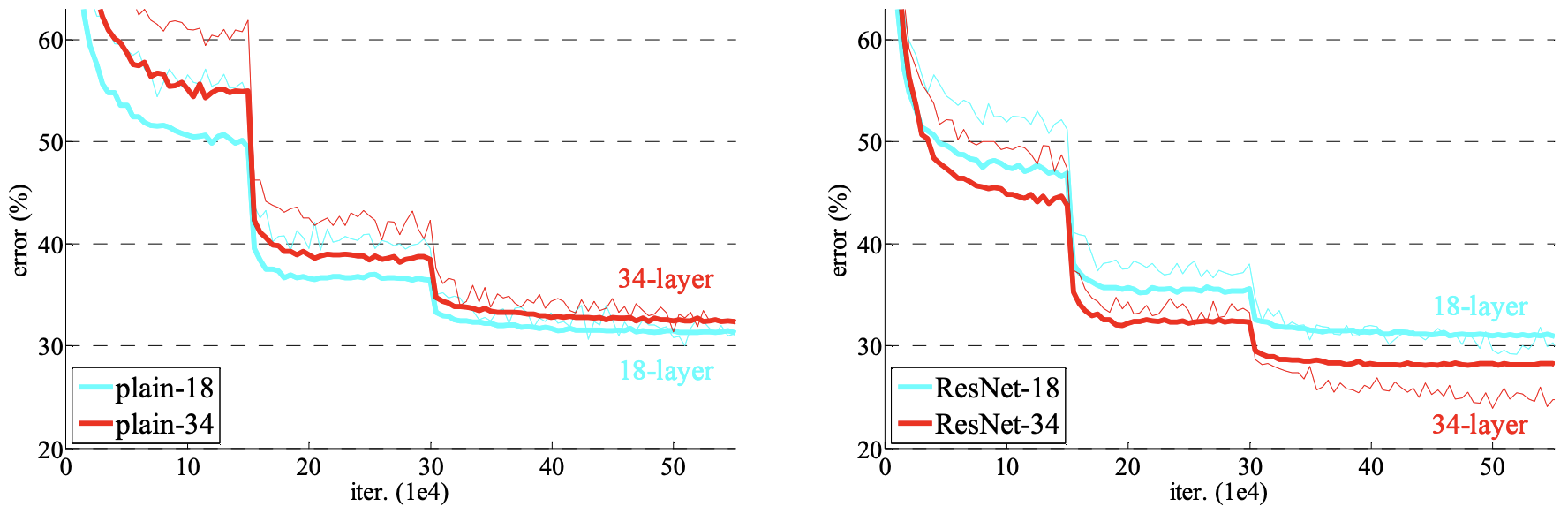
Effekt erst tiefen Netzwerken
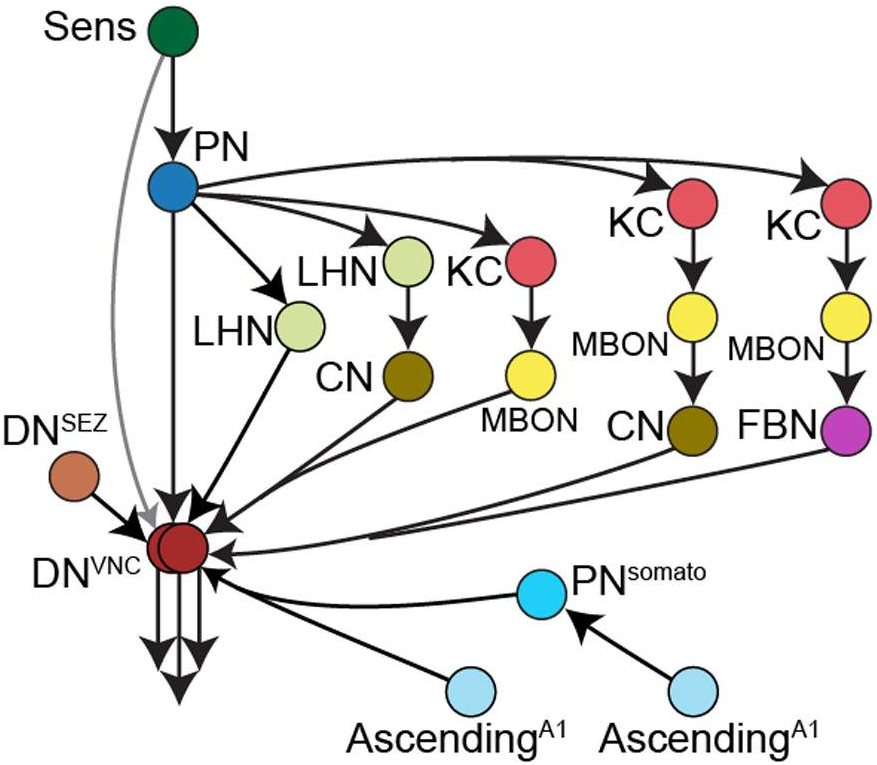
The connectome of an insect brain, 2023
Vision Transformer, 2021
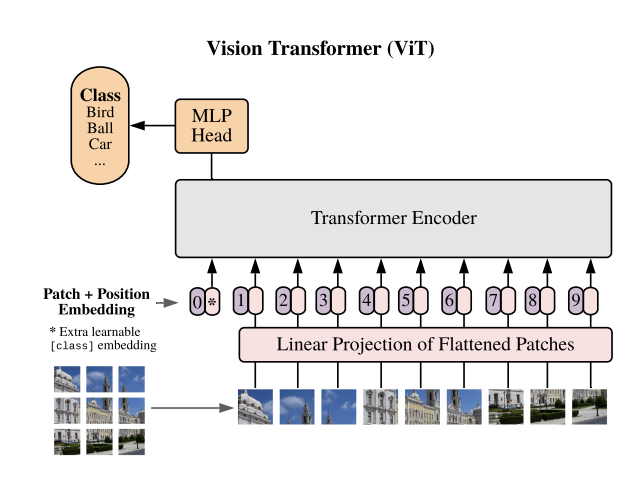
[class] enthält generelle Daten
Transfer Learning
def entries(todo_list, date) do
todo_list.entries
|> Map.values()
|> Enum.filter(fn entry -> entry.date == date end)
end- Vorhandenes Wissen neu anwenden
- Implementierung?
Untere Schichten ähnlich

model = resnet34()ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
...
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential([...])
optimizer = Adam(model.fc.parameters(), lr=1e-3)