DSAI Pt 2
Workflow
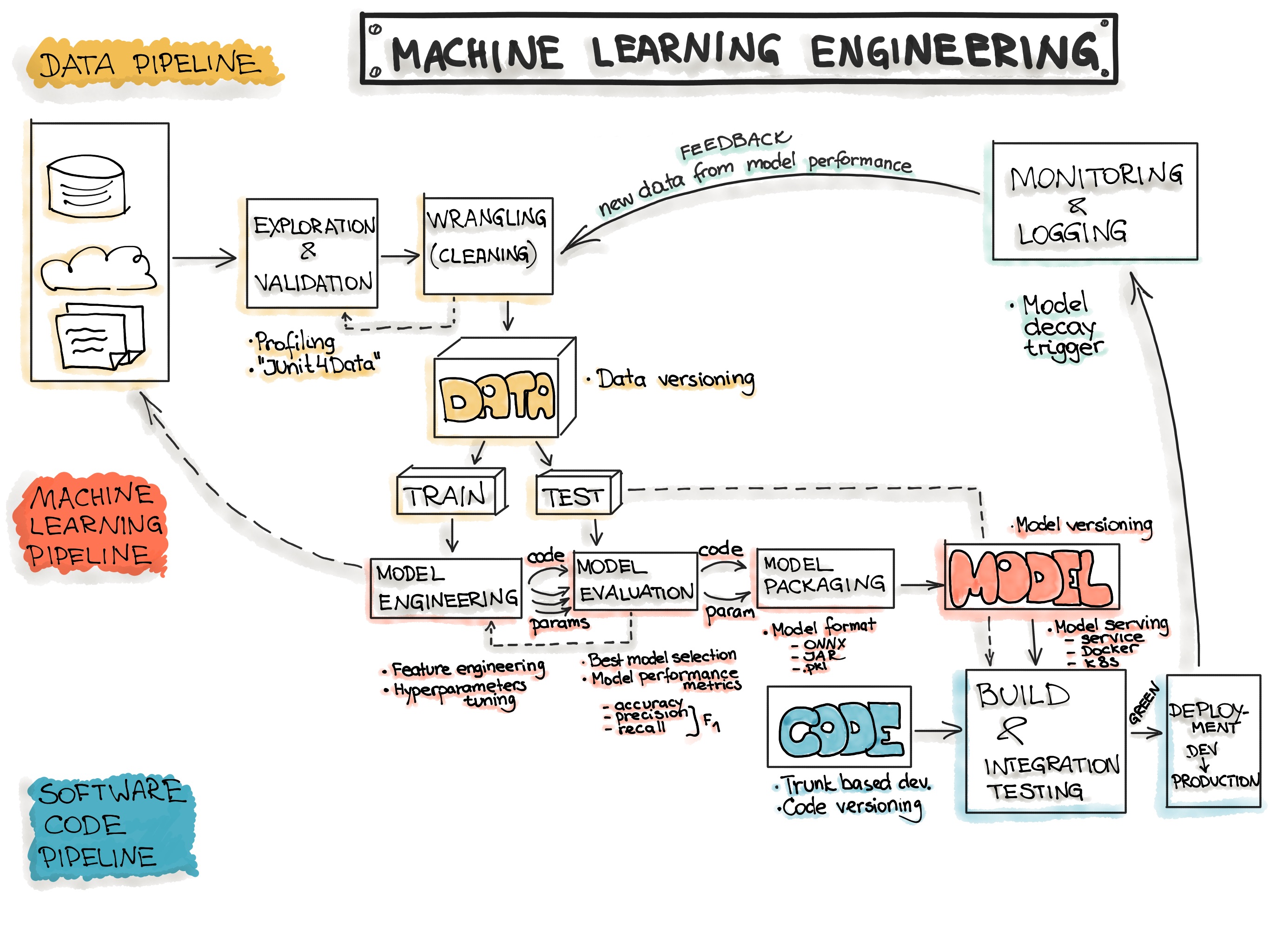
Performancemessung
- Schüler soll Mathe lernen
- lernt das Buch auswendig
- kann alles
- Schularbeitsbeispiel nicht im Buch -> 5
- Trainingsperformance kann lügen
Train-Test-Split
- Daten werden geteilt
- Training mit Trainingsset
- Testset simuliert unbekannte Daten
- Testperformance aussagekräftig

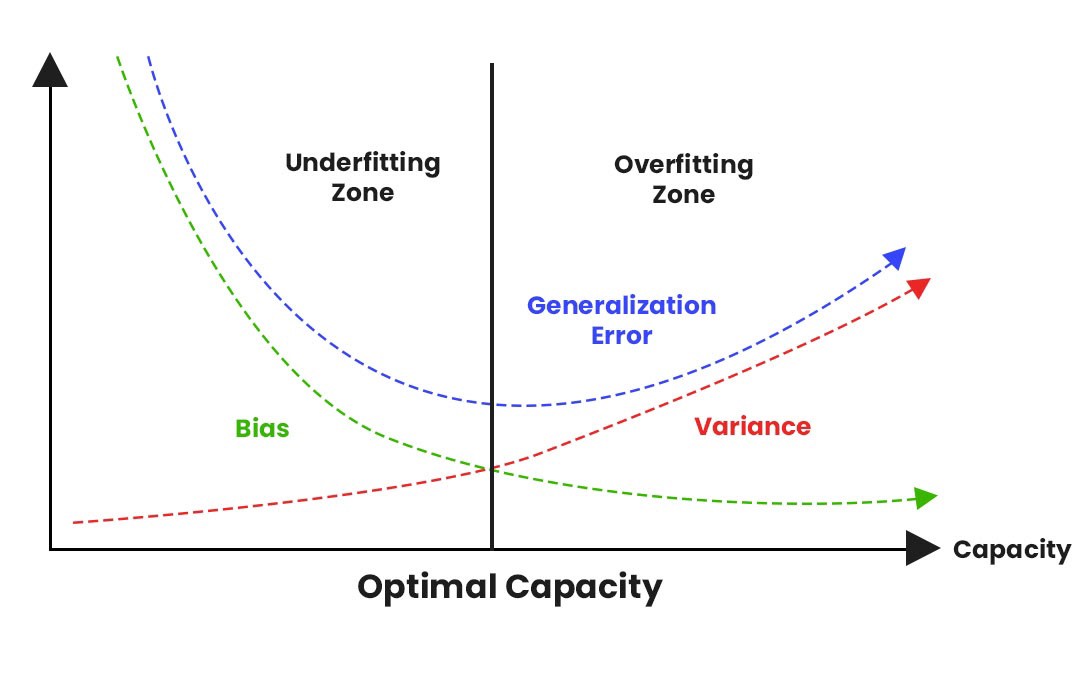
Underfitting/Overfitting
Bias/Variance
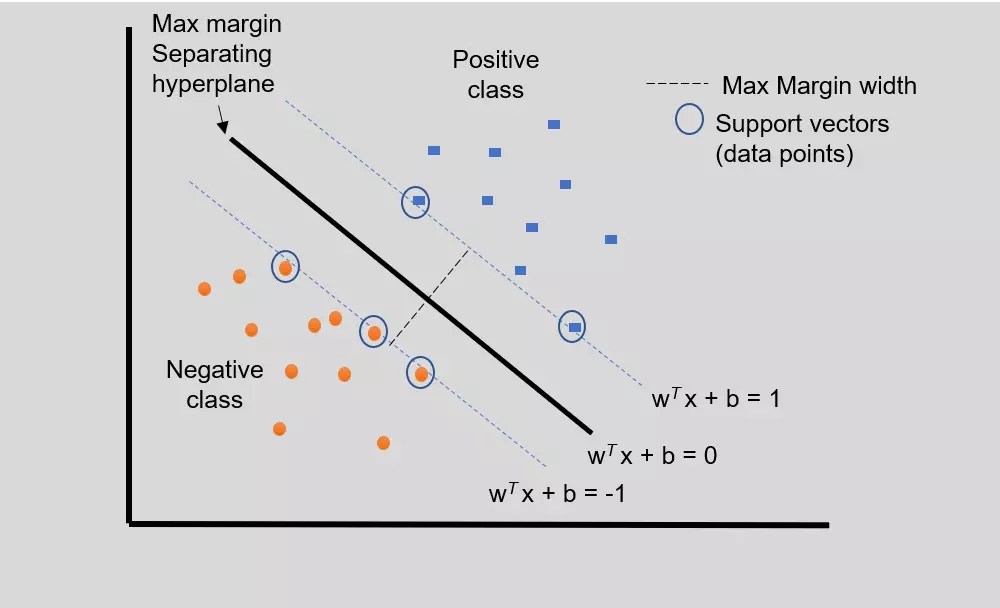
SVM
Kernel Trick
Gaussian RBF
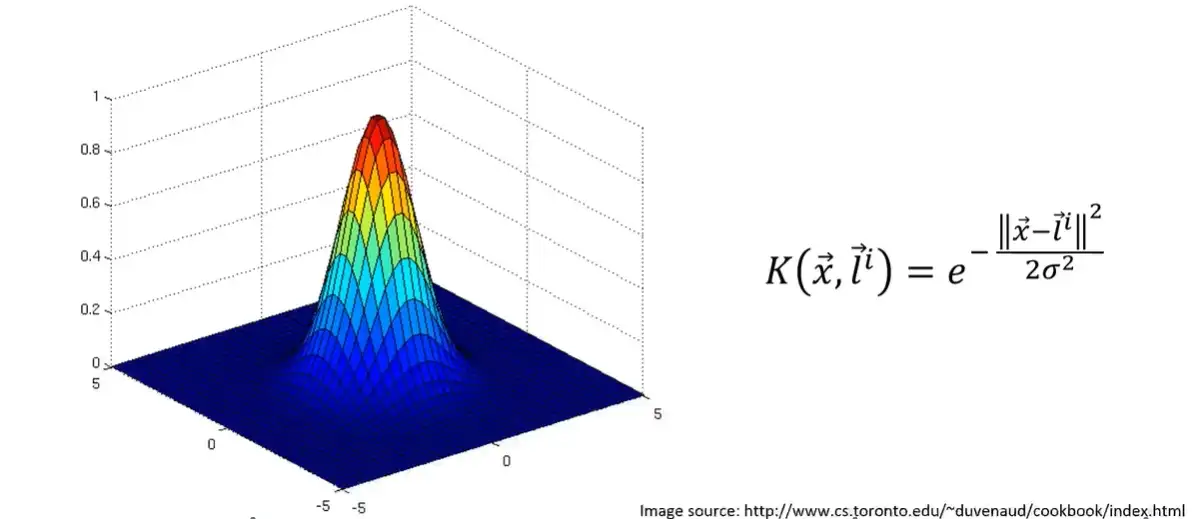
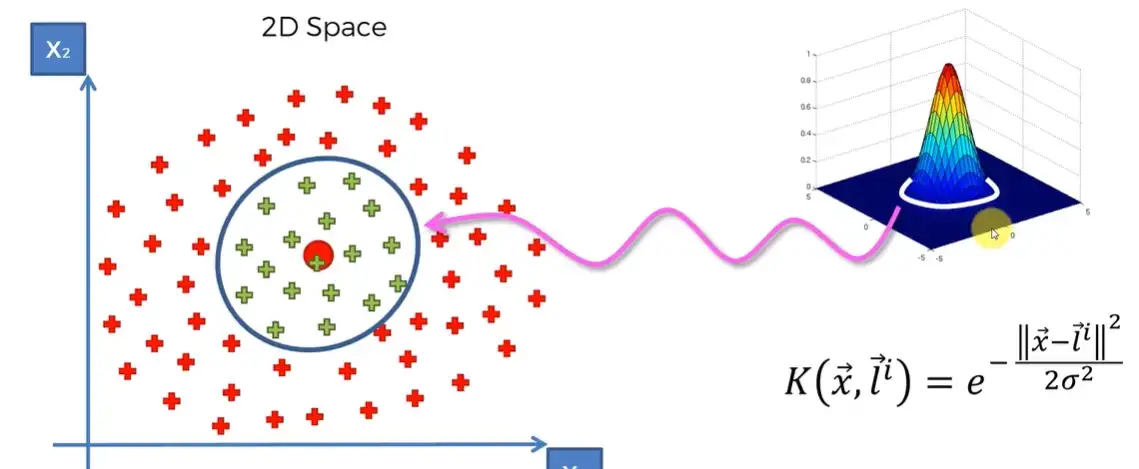
- $$\gamma = \frac{1}{2\sigma^2}$$
- Einfluss einer observation
SVC(kernel='linear', C=100)
C$\frac{1}{C}$ Faktor der $l_2$-RegularisierungC=0.01⟹ training-missclassifies okC=1000⟹ training-missclassifies NEIN- bei allen sklearn-models
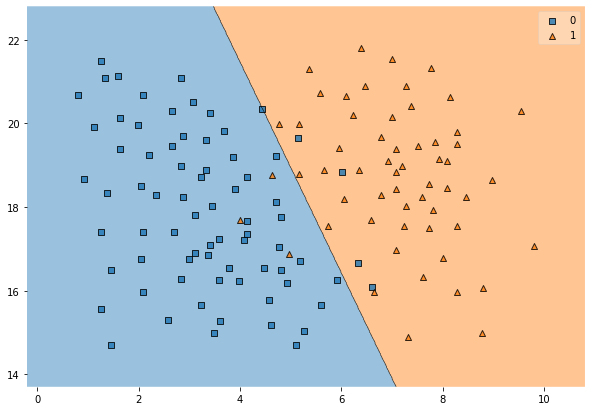
SVC(kernel='rbf', C=100, gamma='scale')
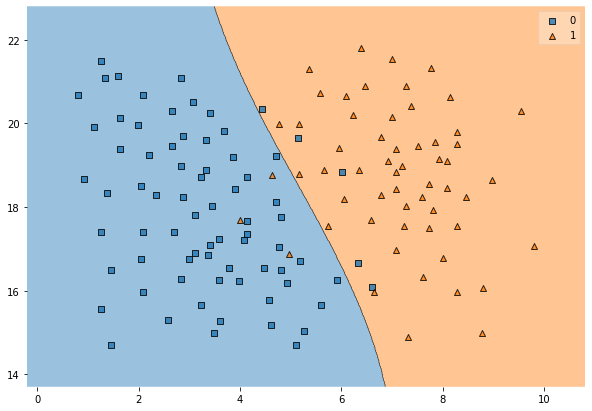
SVC(kernel='rbf', C=100, gamma='auto')
$$\gamma = \frac{1}{n_{features}}$$
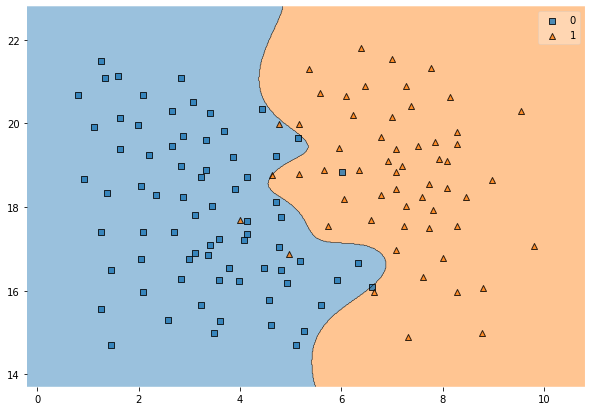
SVC(kernel='rbf', C=500, gamma=1)
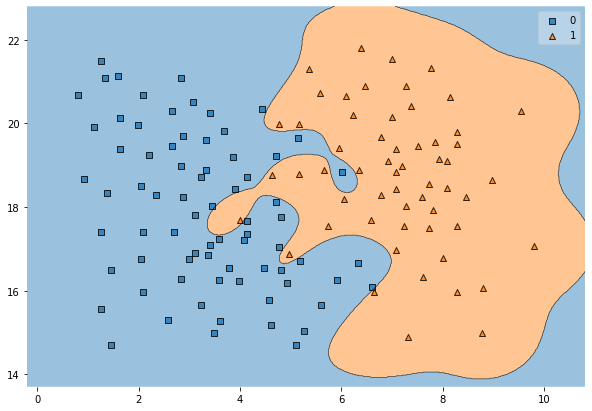
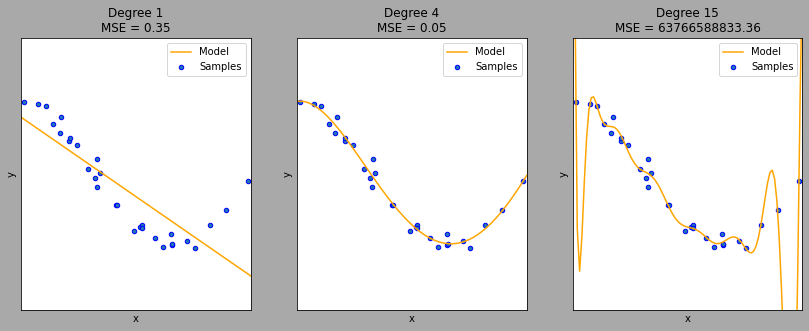
Underfitting
- Model kann sich nicht gut an Trainingsdaten anpassen
Lösung
- Komplexeres Model
Overfitting
- Model passt sich zu gut an Trainingsdaten an
- Model generalisiert schlecht
Lösung
- Komplexität reduzieren
- ANNs: Dropout-Layer
- Model regularisieren
$l_1/l_2$ Regularization
Modell einschränken, damit Parameter $\theta$ klein bleiben
$$cost_{reg} = cost + \lambda\cdot reg$$
$$reg_{l1} = \sum|{\theta}|$$
$$reg_{l2} = \sum\theta^2$$